HDFS通信方式與存儲原理 信息處理和存儲支持的基石
HDFS(Hadoop Distributed File System)作為Hadoop生態系統的核心分布式存儲組件,其設計初衷是為了在商用硬件集群上存儲海量數據,并提供高吞吐量的數據訪問。其獨特的通信方式和存儲原理,共同構成了現代大數據信息處理和存儲支持服務的堅實基石。
一、 HDFS的通信方式:高效協同的基石
HDFS的通信主要基于客戶端-服務器模型,并嚴格遵循主從(Master/Slave)架構。核心的通信協議是TCP/IP,并通過遠程過程調用(RPC)機制進行節點間的通信與協調。
- 客戶端與NameNode的通信:
- 元數據操作:當客戶端需要執行文件系統操作(如創建、重命名、刪除文件或目錄,打開文件讀取等)時,首先會與NameNode建立RPC連接。NameNode作為“管理者”,負責管理整個文件系統的命名空間(目錄樹)和所有數據塊(Block)的元數據(如位置信息)。客戶端從NameNode獲取目標文件的元數據,特別是數據塊所在的DataNode列表。
- 通信特點:這種通信是高頻率但輕量級的,主要交換的是控制信息和元數據,而非實際數據本身。
- 客戶端與DataNode的通信:
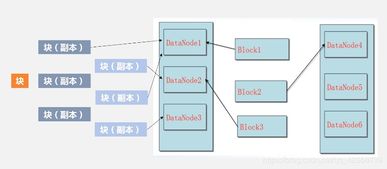
- 數據讀寫操作:在獲取數據塊位置后,客戶端會直接與相應的DataNode建立TCP連接進行實際的數據傳輸。對于讀操作,客戶端從最近的DataNode讀取數據塊;對于寫操作,客戶端將數據寫入管道(Pipeline)中的第一個DataNode,再由該節點轉發給下一個副本節點,以此類推。
- 通信特點:這種通信是數據密集型的,直接傳輸文件內容,是系統吞吐量的關鍵所在。
- DataNode與NameNode的通信:
- 心跳與塊報告:每個DataNode會定期(默認3秒)向NameNode發送心跳信號,以證明其存活。DataNode會周期性地向NameNode發送塊報告,匯報其本地存儲的所有數據塊列表。
- 通信目的:NameNode通過心跳來監控DataNode的健康狀況。如果某個DataNode長時間未發送心跳,NameNode會將其標記為失效,并啟動副本復制流程,將丟失的塊從其他存活的副本復制到新的DataNode上,以維持預設的副本因子(默認3)。塊報告則讓NameNode能夠維護塊到DataNode的精確映射關系。
- DataNode之間的通信:
- 數據管道復制:在數據寫入過程中,DataNode之間會形成一個數據管道,依次接收并轉發數據塊,同時進行本地持久化存儲。這種設計確保了數據寫入的高效性和多個副本的一致性。
- 平衡與恢復:在集群負載均衡或副本恢復過程中,DataNode之間也會直接傳輸數據塊。
二、 HDFS的核心存儲原理:可靠與可擴展的保障
HDFS的存儲原理圍繞幾個關鍵設計思想展開:超大文件分塊存儲、數據冗余備份、流式數據訪問和“移動計算而非數據”。
- 分塊存儲:
- HDFS將大文件切分成固定大小的數據塊(Block,默認128MB或256MB)。分塊帶來了諸多好處:文件大小可以遠遠大于單個磁盤的容量;簡化了存儲子系統的設計(元數據與數據分離);更適合作為數據并行處理(如MapReduce)的基本單位。
- 副本機制與機架感知:
- 可靠性保障:每個數據塊都會被復制成多個副本(默認3份),分散存儲在不同的DataNode上。這是HDFS實現容錯性的核心。當少數副本所在的節點或磁盤發生故障時,數據不會丟失。
- 機架感知策略:為了優化可靠性(避免一個機架斷電導致所有副本丟失)和網絡帶寬(優先利用同一機架內的高速帶寬),HDFS實現了機架感知的副本放置策略。通常,第一個副本放在客戶端所在的節點(或隨機節點),第二個副本放在同一機架內的不同節點,第三個副本則放在不同機架的另一個節點上。這種策略在數據可靠性、讀取帶寬和寫入效率之間取得了良好平衡。
- 命名空間管理與FsImage/EditLog:
- NameNode在內存中維護著完整的文件系統命名空間和塊映射表的鏡像,這使得元數據操作速度極快。
- 為了持久化并保證元數據的一致性,NameNode使用兩個關鍵文件:
- FsImage:文件系統元數據的完整檢查點鏡像。
- EditLog:記錄所有對文件系統元數據的修改操作的事務日志。
- 啟動時,NameNode將FsImage加載到內存,并重放EditLog中的所有操作,以恢復到最新的狀態。Secondary NameNode(或在高可用HA架構中的Standby NameNode)會定期協助合并FsImage和EditLog,防止EditLog無限增長。
- 數據一致性與校驗和:
- 客戶端寫入數據時,會計算每個數據包的校驗和。DataNode接收數據時進行驗證。讀取數據時,客戶端也會驗證校驗和,如果發現損壞,會自動從其他副本讀取。DataNode自身也會在后臺運行數據塊掃描器,定期檢查存儲數據的完整性。
三、 作為信息處理和存儲支持服務的角色
HDFS的通信與存儲機制,使其完美地扮演了底層信息處理和存儲支持服務的角色:
- 對上層計算框架的支持:HDFS通過其高吞吐量的數據訪問能力和“移動計算到數據附近”的特性,為MapReduce、Spark、Flink、Hive等計算引擎提供了穩定、高效的數據源和存儲目的地。計算任務可以被調度到存儲有所需數據塊的DataNode上執行,極大減少了網絡數據傳輸開銷。
- 數據湖的存儲基礎:HDFS能夠存儲各種格式(結構化、半結構化、非結構化)的原始數據,是企業構建數據湖(Data Lake)的理想底層存儲系統,為后續的數據探索、ETL、分析和機器學習提供統一的存儲支持。
- 高可靠與高可用的服務保障:通過副本機制、心跳檢測、故障自動恢復等設計,HDFS能夠提供7x24小時不間斷的存儲服務,滿足企業關鍵業務的數據持久化需求。
- 線性可擴展性:通過簡單地增加DataNode節點,即可線性地擴展集群的存儲容量和聚合吞吐量,能夠從容應對數據量的爆炸式增長。
HDFS通過精心設計的RPC/TCP通信機制實現了高效的集群協同,通過分塊、多副本、機架感知等存儲原理確保了數據的可靠性、可用性與可擴展性。這兩者緊密結合,使得HDFS不僅是一個分布式文件系統,更是支撐整個大數據生態系統進行信息處理和存儲的核心基礎設施服務。
如若轉載,請注明出處:http://m.newscau.cn/product/35.html
更新時間:2026-04-14 21:56:42